Cloud Computing for Business – Buying Cloud Services
Buying and using cloud services follows a lifecycle, in which services are selected and their use is reviewed as a basis for renewing or replacing them.
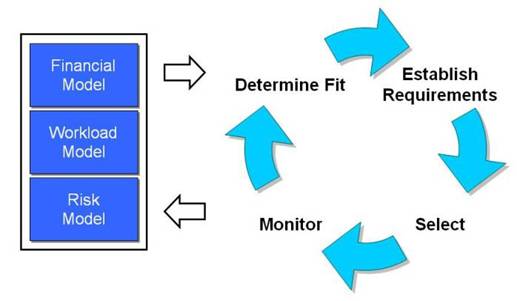
The starting point is your system functional requirement plus a set of models of the solution that you are developing.
In the determine fit phase, you assess how well the cloud services you are considering fit your functional requirements and solution models. This gives you a first-pass filter on those services. It also gives you some additional solution requirements.
In the establish requirements phase, you add to the initial requirements, and establish the complete set of requirements that your candidate services should meet.
In the select phase, you select the successful candidate and agree on a contract. The selection depends on which services best meet the requirements, on what they will cost, and on their terms of contract.
In the monitor phase, you observe the performance of the running services, to see how it compares with what was promised or assumed. The models that you started with, and the set of requirements that you established, form the basis for this comparison.
The results of this phase, and the updated models, form the starting point for the next iteration of the cycle, when you renew the service contracts or select alternatives.
Determining Fit
In establishing your cloud vision, you have achieved an understanding of the business context, and made an assessment of cloud suitability. At this point you should have a good idea of whether cloud services will be part of your solution and what kind of cloud services to consider. The next stage is to see whether those services fit your functional requirements and solution models.
For IaaS or PaaS, the functional requirement is simply for infrastructure or platform; unless you need special features – in which case you should probably not be considering a cloud solution – functional fit is not a problem. For SaaS, you must establish that there are cloud services that meet your needs for application processing. For all kinds of cloud service, you then assess fit with the solution models.
Developing the models for your solution will take time and work. Do not expect them to appear magically as a result of your cloud architecture vision. You should develop the models in collaboration with your enterprise architect and the IT team. The enterprise architect will probably take the lead in this. Expect several iterations, with different versions of the models, before you are satisfied with them.
The important models for choosing and monitoring cloud services are the financial, workload, and risk models. The workload model and the financial cost model are intimately involved in the buying lifecycle. The other financial models, and the risk model, are less directly related.
This section describes the workload and cost models, and how they and the other models are used to determine fit. The descriptions are illustrated by the Konsort-Prinz and ViWi examples. (Sam Pan Engineering is developing a cloud platform rather than buying cloud services, so is generally not relevant here.)
Workload and Cost Models
Your workload model is crucial. It enables you to estimate your cloud service costs. It also enables you to determine your throughput and configuration-speed requirements.
The model describes, in business terms, the amount of processing that the service must handle, and how this varies with the number of users and over time. It also describes, in technical terms, the resources that are used to perform this processing, and it shows how the resources used relate to the processing load.
There is no standard workload model. It is different for every enterprise, and for each service that the enterprise uses.
You can estimate the service costs from the resource usage in the workload model. The calculations will unfortunately be different for each supplier, because suppliers package and describe their resources in different ways. This is particularly so for processing resource; the processing unit offered (and charged for) by each supplier may be different, and it can be hard to relate these units to each other. You have to do this, though, if you want to compare the different offerings. This means that you need a cost model for each supplier.
It is a good idea to note how sensitive the models are to changes in different factors. For example, storage costs may be easier to predict than I/O costs. This information will help you to assess risk, as described in the next chapter (Chapter 5).
Workload Factors
When modeling workload, you should consider variability and predictability, as well as the average or “steady state” value.
Average levels might, for example, be 20 transactions per second and 500,000 transactions per day, with variability between zero and 20 transactions per second, depending on the time of day.
Predictability can be:
- Planned and scheduled – for example, Financial Management (FM) mini-peaks at end of quarter and major peak at end of fiscal year
- Planned and unscheduled – for example, pharmaceutical certification on average five times a year, Florida hurricane response
- Unplanned and unscheduled – for example, air traffic control response to ash cloud
Where predictability is planned and scheduled, you should note its periodicity. This is the cycle of requirements, including average, peak, and off-hours. Cycles may be on a calendar basis (including hourly, daily, weekly, monthly, quarterly, and annually), or on an event basis. Examples are: monthly periodicity, with peaks at the same time each month, and annual periodicity, with seasonal peaks.
You should also consider events with predictable capacity, which don’t occur at the same time each month or year. Examples are weather patterns such as blizzards, unpredictable fads or events, occasions such as weddings, and disasters such as fires.
Think about the growth or shrinkage of your typical steady state usage, including such things as:
- Increase or decrease in capacity at the beginning of each steady state contract year
- One-time changes
- Acquisitions, divestitures, regulatory changes, and new markets
Consider the average and peak number of users by type. Types of user include business users, “power” users, and process administrators.
Workload Allocations
Be aware that there are different types of workload that scale in different ways. This must be taken into account when modeling your workload.
Applications with a large amount of shared memory, many inter-dependent threads, and tightly-coupled interconnections cannot easily be partitioned between processing units, and only scale vertically. Applications with independent threads that do not share memory and have loosely-coupled interconnections can be partitioned, and scale horizontally. Other applications scale to some extent in both directions.
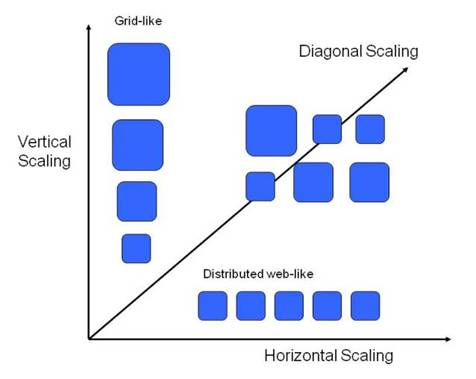
The figure below shows some examples of the different types.
Examples of Workload Allocation Types
Principles to follow in allocating workload include:
- Centralize key services for maximum pooling of total capacity available
- Deploy solutions based on standard commoditized modular building blocks for maximum flexibility and re-use potential
- Automate provisioning of standard images for maximum agility
- Abstract the workload, where appropriate, from infrastructure using virtualization
- Identify workloads that can benefit from moving short-term burst loads to a cloud service
Pay-As-You-Go versus Ownership
Cloud costs are typically lower with short-term burst use but, for a steady or moderately-variable load, buying an on-premise system will probably be cheaper than using cloud services in the long term.
There are pricing options that can make cloud attractive in some long-term scenarios. Reserve cloud instances – cloud resources that are contracted for on a longer-term basis and typically for a lower price than those provided on-demand – lower the cost of long-term use. Burst services enable peak operational demand to be diverted to cloud capacity.
Companies should assess their demand usage models in terms of actual workload profiles versus capacity usage. Many operational workloads are not 24x7x52 and can be accommodated by a combination of reserve instances and spot instances or “cloudburst” facilities. The figures below illustrate this. (Note that 30% OPEX is assumed for hybrid cloud and 25% for on-premise. In a pure on-premise solution OPEX is likely to account for 25% of the annual cost with 75% being interest and depreciation – the CAPEX element. The hybrid cloud solution has a lower proportion of CAPEX and a higher proportion of OPEX because of its public cloud element. These amounts are illustrative of what might be encountered.)
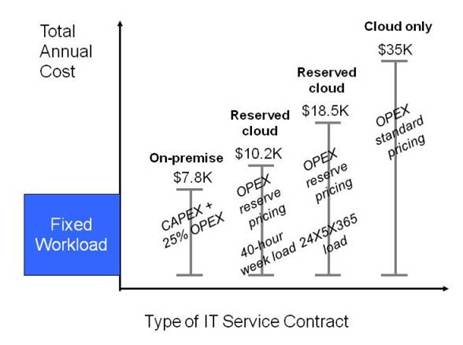
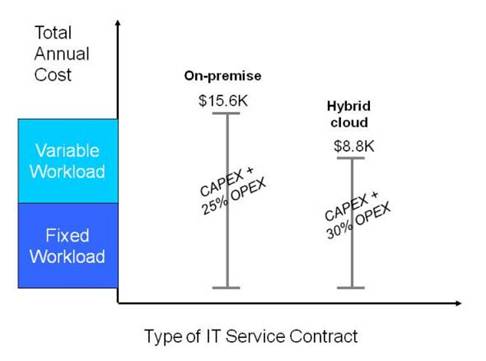
Example Variable Workload Costs
With IaaS and PaaS, you can have a hybrid system, with some processing performed on-premise and some on the cloud. (This is not such a practical possibility with SaaS.) The challenge is to define variable workloads and to be able to turn capacity on and off and switch between off and on-premise services. There are costs associated with this that need to be assessed to “plug into the cloud”.
Modeling Resources and Costs
If you are using SaaS, and the charges relate to business units (such as number of users) rather than computing resources (such as Megabytes of memory), there is no need to build the resources into your model. You build a cost model for each supplier by mapping your business units to the supplier’s charging units. This model enables you to determine your probable costs for a given load.
For PaaS and IaaS, or for SaaS if the supplier charges by resource rather than by business unit, you should model use of processing power, memory, storage, and I/O. These are what most suppliers charge for.
Consider:
- Peak resource level – the capacity you require the supplier to be able to provide
- Usage per time period – which is what you will be billed for
- Rate of resource change – which determines your requirement for speed of provisioning and de-provisioning
Try to express these in standard terms that you can map to the units used by the suppliers you are considering. There may be benchmark figures available that can help you. This is a difficult area, which requires specialist technical expertise. If you do not have this in your IT team, consider employing an external consultant.
Mapping your units to the units used by the suppliers will give you the cost models that you need.
It is sensible to validate the models before relying on them for big decisions. You might develop your own benchmark program and run it with test data using each of the services that you are considering. One of the advantages of cloud computing is that on-demand self-service makes it easy to do this.
Example Workload and Cost Models – Konsort-Prinz
Konsort-Prinz develops a simple workload model. The load is measured by the number of products, the number of customers, and the number of orders. The processing power, memory, storage, and I/O required are calculated from these factors by simple algebraic formulas.
The company has estimates, based on experience, for typical, maximum, and minimum loads for each month of the year. Feeding these into the model gives estimates for the computing resources required, including the maximum at any time and the expected total for a year.
There are large variations in load, but the levels can be predicted with reasonable accuracy, at least a day in advance. The architects plan to provision capacity twice per day, and set a requirement to be able to provision a new resource within one hour. They are confident that this will meet the needs, and do not see a need to model rate of change.
The modelers express processing resource in “computer resource” units based on the existing in-house system. They develop a simple benchmark program based on their model, and calibrate it on the in-house system. They then run it on the IaaS services that they are considering, to validate the model and determine how the services’ units relate to theirs. This gives them a validated cost model for each IaaS supplier.
The end result is that they can calculate the expected annual resource cost for each supplier, giving a vital part of the information the company needs to make the supplier choice.
Example Workload and Cost Models – ViWi
ViWi’s founder draws up a different model. He measures the load in terms of the number of virtual widgets in existence and the proportion of them that are active. Again, the processing power, memory, storage, and I/O required are calculated simply from these factors. Each widget is estimated to require 10 Megabytes of disc storage all the time, and to require 0.1 processing units, 100 Megabytes of memory, and an average of 25 2-kilo-byte data transfers per second when it is active.
He has no real idea of how many virtual widgets the company will sell, or what proportion of the time they will be active. For supplier selection purposes, he decides to assume 100,000 widgets active 5% of the time on average and 20% at peak, giving a maximum of 2,000 and average of 500 processing units, with corresponding figures for memory, storage, and I/O.
The predictability is planned and unscheduled. He anticipates that the workload will change dynamically during the day, with sudden, unexpected peaks. The system will provision resources automatically in response to actual and anticipated demand. He sets a requirement to be able to provision or de-provision a new compute unit plus memory within two minutes, and the system will provision processors and memory at 10% above required capacity to allow for unexpected surges.
He captures the model in a simple spreadsheet.
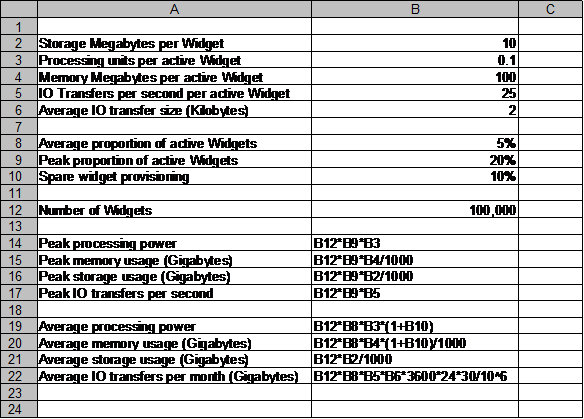
The model expresses processing resource in the units used by one particular cloud provider. ViWi’s founder (and, at that point, the sole developer) deploys an initial proof-of-concept version of the software on that provider’s resources to validate the model, and on other providers’ resources for comparison.
The measure derived from the model that he will use to compare suppliers is cost per widget per month.
Using the Models
Having created a cost model for each service under consideration, you determine the expected cost of using it in the solution, and feed this cost into the overall financial model. You should also use the risk model to assess the risk profile of the solution, as described in Understanding Cloud Risk.
These financial and risk assessments may result in rejection of some cloud services. Indeed, you may reject all the candidate services, and conclude that cloud computing is not the answer after all.
But if you have made a thorough assessment of cloud suitability it is likely that you will have some candidate services at this stage. You have determined fit, and proceed to establish your requirements.
Establishing Requirements
The requirements are conditions that the solution must or should meet. They can be separated into mandatory (must meet) and optional (should meet) classes. When you select a service, you reject those that do not meet the mandatory requirements, and give preference to those that meet the optional requirements over those that do not. When you monitor a service in use, you check that it really does meet the mandatory requirements, and how far it meets the optional ones.
(The workload and cost models may be used to determine requirements, and may help you to express requirements, but they are not requirements as such.)
You are likely to have requirements that relate to use and management of services generally, not specifically to cloud services. Standard practice descriptions of this are available from a number of sources, such as the Information Technology Infrastructure Library [ITIL]. You may wish to refer to one of these descriptions when establishing your complete list of requirements. This section focuses on requirements that are specific to, or affected by, cloud computing.
You will want to describe requirements for functionality, supplier choice, performance, manageability, security, and regulatory compliance. The requirements in these areas that are described in this section are summarized in the table.
Area |
Requirements |
Functionality |
Service Functionality Back-up Bulk Data Transfer |
Supplier Choice |
Supplier Choice |
Performance |
Availability Reliability Recoverability Responsiveness Throughput |
Manageability |
Configurability Reporting Fault Management |
Security |
End User Access Control Provider Access Control Resource Partitioning Logging Threat Management |
Compliance |
Compliance with Regulations |
Cloud Computing Requirements Areas
Different requirement areas may have greater or lesser importance depending on whether you are considering IaaS, PaaS, or SaaS.
Service Functionality
These are the requirements for what the system should do. They are considered as overall solution requirements when establishing the suitability of a cloud solution, as described under Determining Fit, and they then translate directly to requirements on the cloud services that will be the basis of that solution.
IaaS enables the consumer to provision processing, storage, networks, and other fundamental computing resources. You should consider what resources you need. In particular, you should consider what operating system you will use, and whether you will obtain it from the provider.
Konsort-Prinz need UNIX (or Linux) to run their applications, and wish to obtain it as part of the cloud service rather than loading it onto bare computing resources. They note this as a requirement.
Sam Pan Engineering are in the position of providing a cloud service, rather than consuming one. Their users have a mixture of UNIX and Windows applications, and they note that the ability to support both platforms is a requirement on the cloud service that they provide.
PaaS enables the consumer to deploy applications created using programming languages and tools supported by the provider. You should specify both the environment in which the applications will run, and that in which they will be created.
One possibility is that much of the development is done on local machines, and the code is only uploaded to the cloud service for integration, final testing, and deployment. This saves cost, and can dramatically speed up development and unit testing. You should consider this and, if appropriate, specify requirements for it.
ViWi are writing their virtual widget program in Java. They require a Java programming environment and a Java run-time environment. They plan to do most of the development on local machines, using the Eclipse [ECLIPSE] open-source software development environment, and make the ability to support this a requirement also.
SaaS enables the consumer to use the provider’s applications running on a cloud infrastructure. You should specify the functional requirements for such applications just as you would if you were planning to run them in-house.
Back-Up
Regular back-ups enable data to be recovered in the event of system failure. They can also be useful when users wish to correct mistakes that they have made.
The provider may take responsibility for backing up data. In fact, on-premise cloud provider involvement is unavoidable when, for example, tape back-up is being used. You may wish to specify recoverability objectives (see Recoverability below) rather than particular back-up patterns.
In some cases, the back-ups will be your or your users’ responsibility. You should specify the features that the service must have to enable these back-ups to be taken and the data to be restored from them.
Care should be taken that the back-up and restore do not disrupt normal operations.
Konsort-Prinz plans to take a daily back-up, to match the current practice with its in-house systems. It specifies a requirement for their provider to do this, and to keep the back-up copies in safe storage.
Bulk Data Transfer
10 Megabits per second sounds like a pretty good data transfer rate on today’s Internet. But it will take nearly a quarter of an hour to transfer a Gigabyte at that speed; or about 10 days to transfer a Terabyte. We still have to worry about bandwidth when moving the data volumes that are common in the modern enterprise.
You may need to transfer large volumes of data in the normal course of business. You should also think about the need to transfer all of your data if you move to another supplier, as part of your exit strategy.
Some cloud suppliers provide bulk data transfer facilities; for example, using physical transfers on disk packs.
You should consider your possible bulk data transfer needs, and specify facilities to make them feasible.
Supplier Choice
Making it a requirement that there should be other similar suppliers that you could move to if necessary will enable you to have a viable exit strategy. The importance of this is discussed under Selection. It will strengthen your hand considerably in negotiations.
On top of TCP/IP, the cloud uses established standard web and web service data formats and protocols. The programming interface standards on which cloud PaaS offerings are based are equally well established. They include the single-vendor .NET standards and multi-vendor standards such as UNIX, Linux, and Java. As regards basic service functionality, this ensures a reasonable choice of supplier for IaaS and, in theory, for PaaS – though there are not yet all that many PaaS suppliers to choose from.
The situation is different when it comes to configuration and management, which can vary substantially between cloud suppliers, even for IaaS. It is unlikely that standards can make it possible for an enterprise to have a single management regime for all its cloud suppliers, but they should at least make it easier to move from one supplier to another. At present, however, this is academic. Widely accepted standards for cloud service configuration and management do not yet exist. There are several industry bodies working on them, including the Distributed Management Task Force [DMTF], the Open Grid Forum [OGF], and the Storage Networking Industry Association [SNIA].
Availability
Availability, or uptime, is the proportion of the time that a system is available for use. It is commonly described by the number of 9s. A “Five 9s” system is up 99.999% of the time – a little over five minutes per year downtime. Planned, scheduled outages for maintenance are typically excluded.
Availability is important. An uptime of 99.9% means 42 minutes of downtime per month during which you cannot provide service to your customers.
The Uptime Institute [UPTIME] defines a widely-used standard set of availability tiers for data centers, ranging from 99.999% at Tier 4 down to 97.6% availability at Tier 1 (nearly 9 days downtime per year). These levels can be used as a yardstick for cloud service availability. Historically, the better data center service levels (four or five 9s) have not been matched by cloud service providers, but this is changing as reliability and commercial models evolve and the providers develop their recovery and performance management mechanisms.
ViWi wants availability to be in the upper range of what cloud services typically offer. It specifies an availability requirement of 99.9%.
Reliability
In the world of electronic components, reliability of repairable components is expressed as a combination of two parameters: Mean Time Between Failures (MTBF) and Mean Time To Repair (MTTR). For non-repairable components, it is expressed as Mean Time To Fail (MTTF). By analogy MTBF and MTTR can be, and often are, used as a measure of reliability of cloud services.
There is a simple algebraic relation between average availability, MTBF and MTTR [average availability = MTBF/(MTBF + MTTR)]. You would probably not specify reliability as well as availability. You would specify reliability rather than availability if one of the two reliability factors is more important to you than the other.
MTBF and MTTR are average figures. They are useful as indicators of the expected quality of the service, but they are not useful in the context of an SLA. Suppose the MTTR of a service is quoted as 30 minutes and you have an outage of one hour. Is the provider in breach of the agreement, or were you unlucky in suffering a particularly long outage, balanced in the average by shorter ones at other times? In an SLA, you should look for guaranteed maximum number of outages over a period and maximum outage length, and similarly for a guaranteed uptime during any month or year. These figures will of course not be so good as the averages for the service.
Konsort-Prinz believes that its customers will accept failures as part of a normal Internet experience, but that the customers will become frustrated, and perhaps turn to other suppliers, if the system is down for a long time. It therefore puts a higher priority on MTTR than on MTBF, and specifies a maximum outage length.
Sam Pan Engineering, on the other hand, will re-allocate users to another resource if one of its cloud resources goes down, but wants to do this as seldom as possible. Its priority is on MTBF rather than MTTR, and it specifies maximum number of failures per year.
Recoverability
Recoverability is the ability to recover from a failure. It is measured in terms of Recovery Time Objective (RTO) and Recovery Point Objective (RPO). RTO determines how quickly the system needs to be fully operational; RPO determines how much data loss can be tolerated.
RTO and RPO are normally used in the context of catastrophic failures, where there is a possibility of a large amount of data being lost (e.g., the contents of a whole disc), rather than transient failures (e.g., an operating system crash) where just a few records are likely to be lost. These situations should be distinguished; they require different kinds of recovery strategy.
RTO is specified as a time period and includes the time taken to restore data from back-up copies.
RPO can be specified in terms of the number of hours’ data that can be lost. In some applications, such as financial transaction processing, this may be zero – but satisfying such a requirement is likely to be expensive. The daily back-up specified by Konsort-Prinz implies an RPO of 24 hours’ data.
Responsiveness
Response time is the time taken for the system to respond to input. It can be specified as an average with an allowance for variability; for example, “an average of 300 ms with no more than 1% of responses taking more than 800 ms”. Alternatively, a maximum figure may be given; for example, “less than a second”.
When considering the overall system, different response times may be appropriate for different kinds of interaction. For example:
- Product web page displayed in less than two seconds
- Web purchase completed in less than 30 seconds
The time to respond to the end user is the most important response time figure. Unfortunately, you will never be able to specify that to a cloud supplier, because it always includes factors that are outside the supplier’s control. In all cases there are network delays between the cloud system and the end user. For IaaS and PaaS there are also delays due to application software and perhaps other programs that are your responsibility.
The most that you can specify is the processing and communications latency within the cloud system itself. This can be quite low; figures of the order of 1 ms are quoted by some providers. In contrast, for exchange of information over the Internet between a user and the service – which is what most consumers care about – you can expect a latency of 100 ms or more, perhaps even a second or more.
Part of the round-trip delay may be due to slow response by the provider. Cloud system response should be broadly comparable with that found in a non-cloud system. However, higher system utilization generally means slower response, so you should expect the response of a highly-utilized cloud system to be slower than that of an under-utilized system that you have in-house.
Also, there are sometimes additional delays due to virtualization. For example, there is a particular consequence of some resource pooling arrangements that can be a problem – known as “cold start” – on cloud systems. When a virtual processor has not been in use for a certain period, it is removed from its real processor to make room for others. When it is next required, it has to be re-loaded. An application that runs infrequently may thus have to be re-loaded every time, so that the response perceived by the user is very poor indeed. This has little effect on the response time averaged over all applications (which is probably the figure that the supplier will quote) but a big effect on one particular application (which may be the one that matters to you).
The lesson is that it is advisable to understand the cloud supplier’s architecture, and the way that your own software works, when specifying response time requirements.
Konsort-Prinz does not have unusual response time requirements, and believes that its application software will run on the cloud systems with similar response times to those that it has when running in-house. It does not specify a particular response time requirement for the cloud services that it will use. [Its management team is in for a nasty surprise – see Measuring and Tracking ROI.]
ViWi does not have unusual response requirements for user interactions, but it does have a need for frequent, rapid communications between the virtual widgets and a central support processing unit. It specifies latency of maximum 1 ms for these communications.
Throughput
Throughput is the amount of work that a computer can do in a given time period. For transaction processing systems, it is normally measured as transactions-per-second. For systems processing bulk data, such as audio or video servers, it is measured as a data rate (e.g., Megabytes per second). Web server throughput is often expressed as the number of supported users – though clearly this depends on the level of user activity, which is difficult to measure consistently.
The size of each transaction can be important. A system that can process 20 transactions per second, each of which uses a Megabyte of memory, may not be able to process 20 (or even 2) transactions per second if each transaction uses a Gigabyte. Other factors can be important also. The Transaction Processing Performance Council [TPC] defines several different kinds of transaction, with different characteristics, for benchmarking purposes.
The requirements for peak and average throughput should be derived from the workload model, as described above under Modeling Resources and Costs.
Configurability
On-demand self-service is an essential characteristic of cloud computing. Consumers can provision capabilities without requiring human interaction with the service provider. But the facilities provided for this vary between providers. You should consider what facilities you need, and specify them as requirements. These might cover:
- The ability for configuration and provisioning to be done by software, rather than manually
- The speed of provisioning and de-provisioning resources
- The ability to specify particular resource combinations
- The ability to set limits on the amount of resource used
- The visibility and controllability of multi-tenancy partitioning and isolation
For example, ViWi needs to provision and de-provision software resources rapidly and under software control, whereas Konsort-Prinz can accept slower provisioning and de-provisioning, and can do it manually.
Reporting
The reports on system usage and performance must give sufficient information for your purposes.
Reports on usage of billed resources are normal, and form the basis for billing. You may, however, have requirements for additional information to be shown. For example, you might want to know the CPU and memory utilization of the processing units you have deployed. This is the case, for example, for ViWi, whose system uses the information in tuning the allocation of virtual widgets to processing units.
You may also have requirements for the timeliness of these reports. Konsort-Prinz wants the usage reports for each day to be available by 6:00 AM the next morning.
Finally, you may want the reports to be in a particular format, or to be in a form suitable for machine processing. Konsort-Prinz wants them to be clear and easy to read by humans. ViWi wants them in machine-readable XML for software analysis.
Fault Management
Diagnosis and correction of faults in the service will be the provider’s responsibility. You should require adequate procedures to enable you to report faults and check what progress has been made in fixing them. You may require web or telephone helpdesk and support to be available.
End User Access Control
Where cloud services are simply used to replace a component of a conventional IT architecture, as is the case with Konsort-Prinz, the end user access control requirements are similar to those of the conventional architecture. But where cloud computing is leveraged to provide a distributed collaborative environment, a whole host of new issues come into play.
If Konsort-Prinz starts to move beyond its original concept, and thinks about collaborative working with and between its suppliers, it will face some of these issues. What level of collaboration is needed for the supply chain and channels? What information and services must be collaborative and shared?
Once it has decided this, it must address the issue of how to identify the people that will use their system, and how to ensure that those people can access the data, and only the data, that they should be able to access. The traditional approach is to assign everyone a Konsort-Prinz ID and password, but the limitations of this have been apparent for a long time now, and new paradigms of federated identity and access control are emerging.
Selecting an appropriate mechanism for identity and access control for cloud services is still something of a challenge. Organizations that can rise to it will make support for the appropriate protocols a requirement. For SaaS, this means requiring that the services support the protocols. For PaaS, it means requiring that the platform enables you to build and deploy applications that support the protocols. For IaaS, it means finding a standard platform that does this and will run on the IaaS infrastructure.
ViWi is facing these issues already. Its virtual widgets access third-party applications on their owners’ behalf. ViWi intends to use the OAuth protocol [OAuth] for authorization, and makes support for OAuth a requirement for the PaaS service that it is looking for.
Provider Access Control
The ability of system administrators and other staff with special privileges to access restricted information, even when there is no business reason for them to do so, has long been an issue. Cloud computing gives it a new dimension. An in-house system administrator is a staff member, subject to company checks and discipline. The administrator of a public cloud service works for another company and in a remote location where you cannot see what he or she is doing.
This is a problem recognized by cloud suppliers, and some of them have mechanisms in place to control the access that their staff have to customer information.
If security of your data is important to you, you should make provider access control a requirement, and insist that it is a condition of your contract.
Resource Partitioning
An implication of resource pooling on public cloud is that your applications and data may be sharing resources with other programs that could have been written and deployed by anyone. There is nothing to stop a hacker writing a program and running it on a PaaS or IaaS cloud just as you do – and that program could be running on the same physical CPU as yours, and sharing the same memory.
Cloud suppliers do, of course, have mechanisms to ensure that the programs are securely partitioned. But you might still want to make security from access through shared resources a requirement, and a condition of your contract.
You might also want to have some visibility of and control over what other programs are sharing resources with you. You might make this a requirement, but insisting on it will probably restrict your choice.
Logging
A log of user activity is extremely valuable in the event of a security breach, and can also be important for normal activity. It provides an audit trail that helps the system manager to establish what damage has been done, re-secure the system, and take measures to prevent future breaches of the same kind. Security logs have long been common practice. They may be required to comply with legislation, but you may well want one in any case to meet a business need to keep track of user access. You should specify this as a requirement.
Threat Management
Threat management encompasses the disciplines of event, incident, and problem management as defined by ITIL. These are collectively grouped under the term “threat management” for the purposes of our discussion.
You should look at what procedures the service provider has for evaluating and responding to identified security threats. If a security breach does occur, much of the remedial and corrective work must be done by the service provider. You should make it a requirement that the supplier has procedures that meet your needs.
Compliance with Regulations
Many legal regulations preclude using the cloud as-is. For example, the EU Data Protection Directive 95/46/EC imposes restrictions on where personal data can be held. Apart from the legal regulations, contractual or moral obligations may require you to take care that information is kept confidential, or to guarantee that it is not lost or destroyed. Can you meet these obligations when the data is on the cloud?
You should identify the obligations that impact on your ability to use cloud services. The following are examples that apply in certain jurisdictions. Similar legislation may apply in other jurisdictions.
- The EU Data Protection Directive 95/46/EC [EU 95/46/EC], which applies to the processing and movement of personal data
- The US Sarbanes-Oxley Act of 2002 (SOX) [SOX], which was enacted as a reaction to a number of major corporate and accounting scandals such as that affecting Enron, and sets standards for corporate auditing, accountability, and responsibility
- The US Federal Information Security Management Act of 2002 [FISMA], which requires federal agencies to implement information security programs
- The US Gramm-Leach-Bliley Act [GLBA], which provides limited privacy protections against the sale of private financial information
- The US Health Insurance Portability and Accountability Act of 1996 [HIPAA], which includes provisions that address the security and privacy of health data
- The International Standards for Assurance Engagements (ISAE) No. 3402 [ISAE 3402] or the Statement on Standards for Attestation Engagements (SSAE) No. 16 [SSAE 16], which mirrors and complies with ISAE 3402 and effectively replaces the Statement on Auditing Standard 70 (SAS 70) Type II; these standards apply to assessment and audit of the internal controls of service organizations
- The US Department of Defense (DoD) Information Assurance Certification and Accreditation Program [DIACAP], which defines the risk management process for DoD information systems
- The Payment Card Industry Data Security Standard [PCI-DSS], which states international security requirements for protecting cardholder data
For each of the obligations that impact on the cloud services that you use, specify requirements on those services that will ensure that you comply.
Unfortunately, the industry does not in general have adequate certification schemes that assure compliance and QoS delivery of cloud services to customers. In addition, most providers will not allow external audits to be conducted. This leaves the customer in a difficult position, especially towards external regulators. The Open Group has done significant work on the automation of regulatory compliance, resulting in the publication of the Automated Compliance Expert Markup Language standard [O-ACEML], but it has no current plans for a certification program.
Konsort-Prinz will hold some personal data on its system. To comply with EU legislation, the company makes it a requirement that the resources and networks used by the IaaS service that it uses should be located in the EU.
Selection
Once you have determined the costs of using the services, and established the requirements, you can review contract and delivery terms, negotiate to try to reduce price or improve performance, and select your preferred service. But, before doing these things, consider the question of exit strategy.
Exit Strategy
Vendor lock-in has been an issue for customers of IT systems since the early days of computing. Developing open, vendor-neutral IT standards and certifications to enable interoperability and prevent lock-in is the primary role of The Open Group.
The battleground has changed over the years. At first, the concern was with operating systems and applications portability, then with networks and interoperability. Now that we have a reasonable degree of portability, and the Internet has solved the problem of network interoperability, The Open Group is working to improve access to integrated information, within and among enterprises: its vision of Boundaryless Information Flow.
Cloud computing is opening up a new front. The protocol, data format, and program interface standards for using cloud services are mostly already in place. This is why the market has been able to grow so fast. But standards for configuration and management of cloud services are not yet there. And the crucial contextual standards for practices, methods, and conceptual frameworks are still evolving.
Cloud computing will not reach its full potential until the management and contextual standards are fully developed and stable. While these standards are being developed, enterprises will find it harder to use the cloud than it should be. In particular, they will find it harder to change cloud suppliers. It is tempting to call for instant solutions, but history shows that effective standards can only be created in the light of experience.
Today it may be easy to switch mobile phone providers, but the ease of switching cloud providers is still largely untried. As the market becomes more competitive, we would expect the transition between service providers to become easier.
When negotiating with a new supplier, or re-negotiating with an existing one, or if you wish to in-source a particular service, you should be sure that you have an exit strategy – a way of moving to another supplier if you wish to do so.
Insisting on requirements for supplier choice and bulk data transfer will help you achieve this. You should also consider the contract terms (discussed in the next section) and the cost of making the change. You will have to pay for any bulk data transfer – different suppliers charge different amounts. You may also need to convert the data to different formats, re-write software, re-test your solution, and re-educate users.
The problem is relatively straightforward for IaaS and PaaS, because the processing logic is supplied by the user, and the data is likely to be stored in a standard form. It is wise to check, though, that the particular standard formats that you use can be supported by other cloud providers, or that there is a transformation mechanism. For example, if you use SQL, can you easily migrate to a cloud provider that supports persistent data objects? A project that faced this problem recently found that it took two months of solid programming effort to make the change.
The problem is typically harder for SaaS, because the processing logic is supplied by the provider, and the data formats may be proprietary. (This is similar to the situation with a purchased application deployed in-house.) It is unlikely that another provider will have the same processing logic, and a change of provider will therefore probably mean changes to the business processes. Custom code may be needed for data transformation.
Contract Terms
Contracts cover a wide range of aspects, and may be complex. See Legal and Quasi-Legal Issues in Cloud Computing Contracts [MCDONALD] for an overview. This book does not aim to be a comprehensive guide to them, or to give legal advice.
Here are some key questions that relate specifically to cloud computing that you should ask when reviewing cloud service contracts:
- Who owns the data and, for IaaS and PaaS, who owns the programs? What rights does the service provider have over them?
- How long does the contract last, and what possibilities do you have for early termination? This is important for your exit strategy.
- What possibilities does the supplier have for early termination? This affects the risk that you take.
- Does the contract introduce dependencies so that, for example, you can only use the service if you are also subscribed to a different service? This is important for your exit strategy too.
- What is the SLA? This defines the service levels, particularly for performance, that the supplier contracts to support. Typically, it will not cover all of your performance requirements.
- What happens if the supplier does not meet contracted service levels? Some allowance for downtime is routinely made in the contracts with cloud providers, but it is difficult to reclaim losses over and above a refund of the fees charged by the provider. You may want to be able to terminate the contract if the supplier persistently fails to perform.
- Where will the data be located? Can you ensure that it is located in a particular place? You may need to do so to comply with regulations that affect you.
- What security mechanisms does the supplier implement? Particular mechanisms may be needed to comply with regulation.
- What jurisdiction applies? If you have to take the supplier to court, will you have to do it in a foreign country?
- Can the supplier subcontract? If so, do the responsibilities – for example, for meeting service levels – remain with the supplier, or pass to the subcontractor?
Negotiation
It is not usual to modify standard contractual arrangements, especially if the purchasing company is small and the supplier is large, or if cloud computing is being purchased by the business users and not by the IT department.
Konsort-Prinz feels that it may be able to modify the contract terms of the smaller IaaS providers that it is considering. ViWi sees no chance of doing this with its potential providers (at least until virtual widgets become wildly successful).
If the functional characteristics of your workload are complementary to the other workloads enabled by a provider (i.e., if your workload improves the provider's diversity factor), then your business will be more attractive to that provider, and you may be able to negotiate better terms and conditions. (Konsort-Prinz is unfortunately not in this position, as its peak is likely to coincide with high traffic from other service consumers.)
Even though you cannot modify the standard conditions, it is often possible to select the best combination from a range of options published by the seller.
Duration of contract is a particular example. Traditionally, this might be a point for discussion during negotiations. A cloud supplier may not be prepared to discuss it, but may offer a range of different packages in which the buyer commits to the service for different lengths of time, and pays different prices. Capability can be purchased on demand, but “reserved” resources cost less than “spot” purchases, and the longer you reserve them for, the less they cost.
Choosing the Service
The choice of supplier is made by trading off the factors of cost, risk, ability to meet requirements, exit strategy, and terms of contract.
Cost is determined from supplier cost models, as described earlier in this chapter, and risk is assessed through the risk models described in the next chapter.
You should prioritize your requirements, identifying those that must be met and those that you are willing to drop in order to reduce cost or risk. For example, you may decide that the peak availability and throughput requirements must be met, but the response time requirements may be diminished. You may have to make similar compromises on exit strategy or contract terms.
Konsort-Prinz has a good choice of IaaS suppliers, including large international ones and some small local ones. It can negotiate better terms with the smaller suppliers, but assess these as being of higher risk. It has no serious problems with exit strategy; the application runs on a standard platform, the data will not need conversion, and its volume is not enormous. There are no major difficulties with contract conditions. It decides to partner with a regional supplier that offers good terms, accepting the higher risk as compared with a large international supplier.
ViWi is in a very different position. It cannot find a single PaaS supplier that meets all of its specialized and stringent requirements. There is one (which it is already using for initial development) that comes close. The founder decides to consider IaaS as an alternative. He finds an IaaS service that, with a standard platform, meets more of the requirements than most of the PaaS suppliers.
He develops cost models for two PaaS providers and one IaaS provider. These show similar figures, with a reasonable cost per widget per month in each case. (The example figures have been taken from the public websites of real cloud providers, but the names are omitted as the authors do not wish to advertise particular companies, or to risk people forming judgments on them from isolated examples of their pricing structures.)
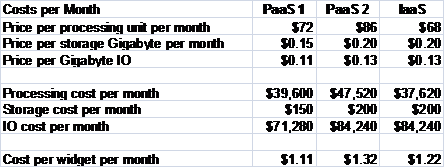
The first PaaS provider meets the requirements best, and comes out best for cost too. The founder is concerned at not having a good exit strategy, but there is little that he can do about this. He chooses the first PaaS supplier, and makes contingency plans for an exit strategy in which ViWi would use the IaaS supplier’s infrastructure and a standard platform that is as similar to their PaaS supplier’s platform as possible. This would, however, still mean significant software re-development costs.
Monitoring
While the service is in operation, you should monitor how well it agrees with your workload and cost models, and how well it conforms to the requirements. The results will help you assess whether to renew the service contract, renegotiate a different contract with your supplier, or change to a different supplier. They will also feed in to your ROI and risk assessments, as described in the next two chapters.
Workload and Cost
By monitoring workload and used cloud capacity you can see how well your model is working, and keep control of your costs.
Konsort-Prinz keeps track of used and provisioned processing power. This shows that the provisioned processing power has, as planned, been much lower for most of the year than what was used on the in-house system.
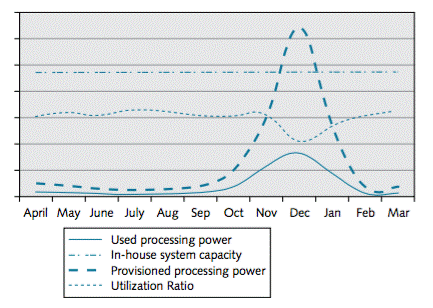
Konsort-Prinz Capacity Utilization
It is still, however, higher than necessary. Utilization of the purchased cloud capacity was only about 33%. The figure below, showing hourly utilization for the peak day in December, explains why.
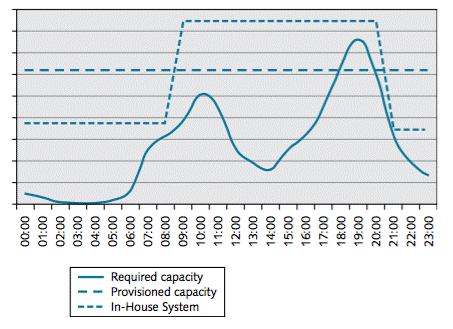
Konsort-Prinz Peak Day Utilization
The twice-daily provisioning cycle does not have sufficient granularity. It is just providing sufficient capacity in the on-peak period and in the off-peak period, but this is still much more than is needed at the troughs of the daily cycle. It looks as though there is scope to improve the return further, by fine-tuning the provisioning. This would, however, be difficult, given Konsort-Prinz’s “vertical scaled” architecture. Changing the system configuration is rather an upheaval, and even the twice-daily cycle is proving to be a strain. With a more modern software architecture, based on loosely-coupled services that could be separately provisioned with resource, the company would have been in a better position to take full advantage of the utilization improvement offered by the cloud.
It monitors actual and projected costs over the first year of operation.
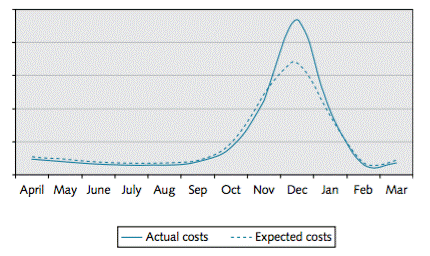
Konsort-Prinz First-Year Costs
This shows a very good fit of actual to projected costs. The discrepancy in December is largely due to inability to match capacity to load quickly enough in a period of rapid change. [There is a story behind this, which will be told in Understanding Cloud Risk.] Despite this discrepancy, the fit to the model is close enough. The company executives consider that the new system has pretty much met their cost targets, and they are happy with their supplier on this score.
Conformance to Requirements
In many cases, conformance to requirements is “yes” or “no”. The service either does or does not perform the required functions, does or does not support the specified protocols, and so on. But for performance requirements, and some others, it is less clear. Suppose that availability was specified at 99.9% and was measured over the year at 99.7%, for example. This may not represent a serious discrepancy in most business environments.
One approach is to rate the values on a simple scale, from unacceptable to excellent, and mark them up on a scorecard. The figure below shows a comparison of performance and manageability parameters for the Konsort-Prinz cloud-based system with its previous system, using this approach.
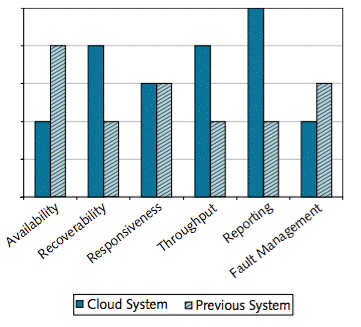
Performance and Manageability Comparison
The new cloud-based system is better in several areas. Recoverability and throughput have improved. The in-house system was struggling to cope with peak workload, and the availability of increased Capacity on Demand (CoD) has made a big difference to the performance of the system at busy times. And the reports from the service provider are very clear, and provide much better utilization information than the company had before. But there are two areas of concern. System downtime has been a problem, and the response of the supplier when faults have occurred has not been good.
They use a similar approach to look at whether performance was within or outside contracted values and the SLA, as shown below. (Good performance is indicated by points near the center, poor performance by points near the edge.)
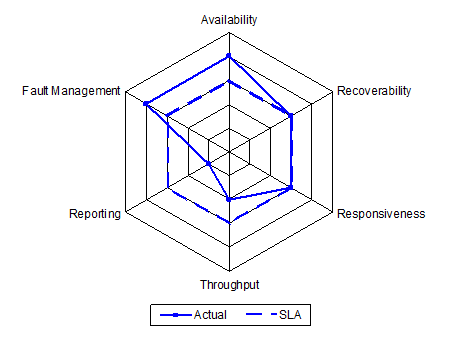
Comparison of Actual Performance with SLA
This confirms that supplier performance on availability and fault management has not been as good as promised. Konsort-Prinz will raise this with the supplier when the contract comes up for renewal, and will change supplier unless it receives satisfactory assurances that availability and fault management will improve.
ViWi’s founder is not at this stage worried about performance and manageability. His main concerns as they move towards launch are with the financial model and with risk. These topics are for the next two chapters.